
Muss es immer »Die Cloud« sein? – Eine technische Betrachtung für die Bereitstellung von IT-Anwendungen (Teil 2)
Muss es immer »Die Cloud« sein? – Eine technische Betrachtung für die Bereitstellung von IT-Anwendungen (Teil 2)

Muss es immer »Die Cloud« sein? – Eine technische Betrachtung für die Bereitstellung von IT-Anwendungen (Teil 2)
von Jan Gottschick
IT-Fachverfahren werden üblicherweise bei öffentlichen IT-Dienstleister:innen bereitgestellt. Entsprechend muss man sich an die dort gegebenen technischen Rahmenbedingungen halten. Cloud-Technologien wie Container-as-a-Service (CaaS) sind bei den öffentlichen IT-Dienstleister:innen bisher selten verfügbar. Daher ist es wichtig, alternative technische Übergangslösungen für das Deployment zu finden und zu nutzen, um trotzdem eine moderne Implementierung des IT-Fachverfahrens bspw. mittels Microservices zu ermöglichen und mittelfristig weitere Reimplementierungen des IT-Fachverfahrens zu vermeiden.
Im vorherigen Beitrag haben wir dargestellt, dass moderne IT-Anwendungen aus heutiger Sicht idealerweise mit Cloud-Technologien wie CaaS umgesetzt werden sollten, es aber auch technische Alternativen für das Deployment von cloudbasierten Anwendungen gibt, insbesondere für eine Übergangszeit. Die Bereitstellung der »Rechner« in einem »Cloud-Cluster« für die verteilte Anwendung kann dazu auf Basis von physischen Rechnern (»Bare-Metal«), auf »virtuellen Servern« (IaaS) oder auf »Containern« (CaaS) erfolgen. Wesentlich ist aber gemäß den essentiellen Merkmalen des Cloud-Computing, dass die Bereitstellung der benötigten IT-Ressourcen durch die IT-Dienstleister:innen insbesondere »vollautomatisiert und bei Bedarf« sowie mittels Selbstbedienung (»On-demand self-service«) erfolgen sollte. Die Selbstbedienung kann über ein Portal (»Web-Portal«) ermöglicht werden oder über eine offene Schnittstelle (API) mit einem API-Server erfolgen. Letzteres ermöglicht einen durchgängig automatisierten, medienbruchfreien Prozess von der Entwicklung bis zum Deployment (»Continuous Deployment«, CD) für die Kund:innen (Auftraggeber:in).
In diesem Teil wird konkret dargestellt, welche technischen Lösungen es für das Deployment (Installation, Pflege) gibt, wenn IT-Dienstleister:innen kein CaaS- bzw. IaaS-Angebot offerieren oder keine Selbstbedienung und Schnittstellen zur Automatisierung anbieten. Die technischen Varianten sind vor allem aus der Sicht der Kund:innen interessant, um die IT-Fachverfahren zeitnah in den Betrieb zu überführen. Dabei sollte die technische Lösung für das Deployment unabhängig von der Fachlichkeit sein. Außerdem sollte (und kann) die Implementierung der IT-Anwendungen größtenteils unabhängig von der Zielplattform des IT-Betriebs realisiert werden, d.h. ohne Vendor-/Provider-Lock-in. Diese zwei Anforderungen sind die Grundlage für die folgenden Betrachtungen.
Cluster
Um zu verstehen, wie das Deployment technisch realisiert werden kann, zunächst ein Überblick, wie eine typische Konstellation für die Bereitstellung verteilter IT-Anwendungen aussehen kann. Die Konstellation der IT-Ressourcen und IT-Dienste für ein verteiltes System ist dabei fast immer gleich und damit unabhängig von der Zielplattform der Betreiber:innen und der technischen Deployment-Lösung. In Abbildung eins ist vereinfacht das Schema eines »Clusters« dargestellt, unabhängig davon, welche technische Umsetzung später gewählt wird.
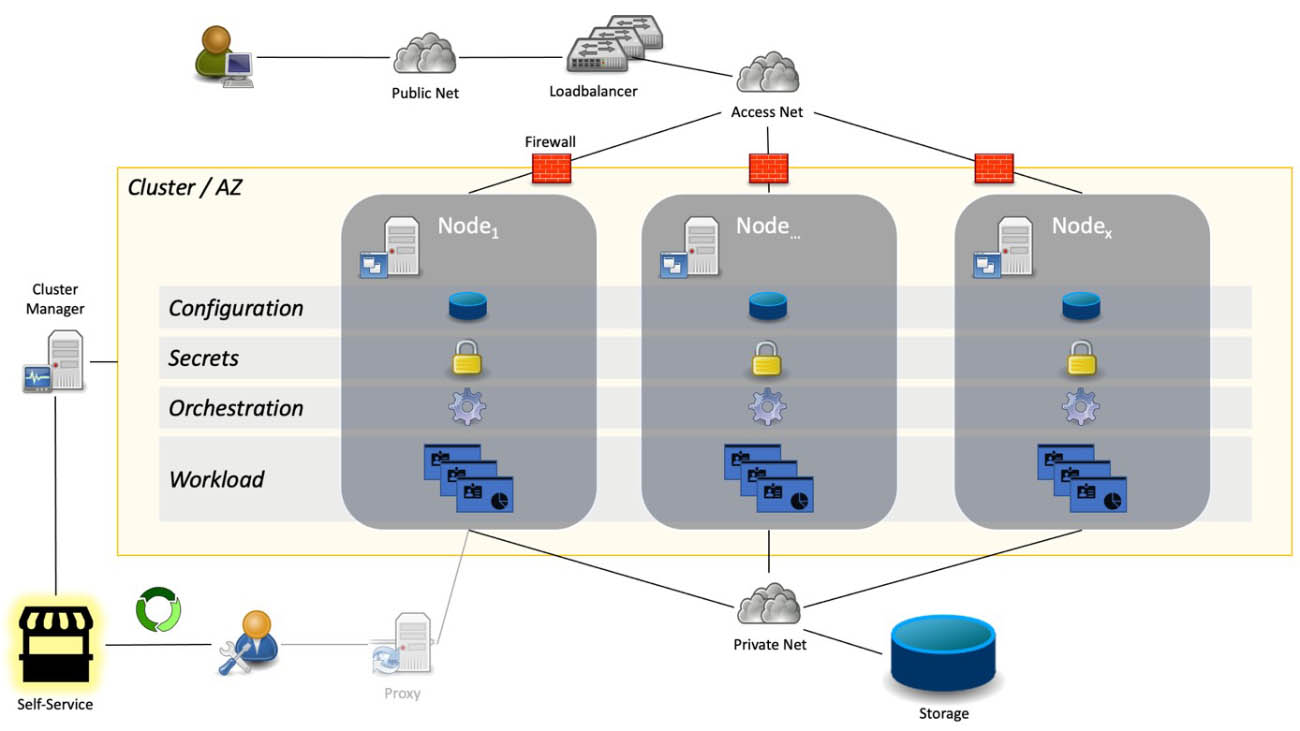
Damit die IT-Anwendung (der Workload) redundant und skalierbar bereitgestellt werden kann, muss diese auf mehrere Server (Nodes) Node1 bis Nodex (Bare Metal oder virtuelle Maschinen) innerhalb eines Clusters verteilt werden. Typischerweise werden wegen der Ausfallsicherheit drei, fünf oder mehr Nodes für ein Cluster benötigt. Der ebenfalls redundante Loadbalancer verteilt Anfragen aus dem »öffentlichen« Netz (»Public Net«), in dem die Nutzenden sich mit ihren Endgeräten befinden, an diejenigen Nodes über das Zugangsnetz (»Access Net«), auf denen die IT-Anwendung aktuell verfügbar ist. Die IT-Anwendung muss dazu nicht nur auf einem Node installiert sein, sondern sie muss auch aktuell erreichbar sein. Dies muss sie mittels »Live«- und »Ready«-Tests über ihre API signalisieren. Eine oder mehrere Firewalls verhindern unerwünschte Zugriffe auf das Cluster bzw. die Nodes. Für die sichere interne Kommunikation zwischen den Nodes wird zusätzlich ein privates Netz (»Private Net«) benötigt.
Neben dem eigentlichen Workload (IT-Anwendung, …) werden weitere unterstützende Dienste benötigt. Der Dienst »Configuration« speichert generell Konfigurationsinformationen, aber vor allem auch den aktuellen Zustand des Clusters. Für die Autorisierungen von Diensten untereinander und gegenüber externen Diensten werden Zertifikate, Token und Passwörter (Secrets) benötigt, die sicher abgelegt werden müssen. Um insbesondere den Workload optimal entsprechend den verfügbaren IT-Ressourcen (wie Rechen- und Speicherkapazität) auf die Nodes gleichmäßig zu verteilen, wird ein Orchestrator benötigt, bspw. eine Open-Source-Software (OSS) wie Nomad oder Kubernetes. Ob der Workload und die genannten Management-Dienste zusammen auf einem Node oder auf separaten Nodes ablaufen, ist im konkreten Fall zu entscheiden.
Darüber hinaus kann es diverse verlässliche, zentrale Dienste außerhalb des Clusters geben, bspw. Storage, Objektspeicher, Git-Repository u.v.m. Die Bereitstellung (Provisionierung) eines Clusters mit allen seinen genannten IT-Ressourcen sollte vollautomatisiert durch einen »Cluster Manager« erfolgen, d.h. einem Management-System zur Steuerung des Clusters. Dieser wird idealerweise durch die Systempflege in Selbstbedienung manuell oder auch automatisiert (über APIs) angesteuert. Der direkte Zugriff auf das Cluster mittels eines Terminals oder einer Web-UI für die Fehlersuche, Pflege und Wartungsarbeiten durch die Systempflege und andere Berechtigte erfolgt in der Regel abgeschottet über einen speziellen Proxy bzw. Management-Dienst.
Automatisierungen
Das Deployment der Anwendung der Kund:innen auf solch ein Cluster sowie das Management des Clusters selbst soll automatisch erfolgen. Die Ausgangslage bilden aber oftmals die heute noch vielfach üblichen Installationsanleitungen und Betriebshandbücher, die Teil der Auslieferung der Softwareentwickler:innen sind und im Wesentlichen händisch ausgeführt werden. Die Absprachen zwischen Software-Entwicklung, Systempflege und IT-Betrieb erfolgen dabei größtenteils per Trouble-Ticket-System. Das händische Deployment wird zwar teilweise durch einzelne Installationsskripte oder grafische Installer ergänzt, aber eher selten systematisch durch Installationspakete (wie dpkg und andere). Dieses Vorgehen ist aber nicht sehr effizient. Als Alternative gibt Abbildung zwei einen Überblick über die Möglichkeiten der Automatisierung des IT-Betriebs, sowohl aus historischer Sicht als auch in Bezug auf den Stand der Technik. Dies bedeutet letztlich, dass auch der IT-Betrieb selbst weitestgehend digitalisiert werden muss.

Konfigurationsmanagement
Den Anfang zur Automatisierung machten klassische Konfigurationsmanagementsysteme, wie bspw. die OSS Ansible, u.v.m. Diese haben ihren Ursprung in der Automatisierung von klassischen Installationsanweisungen, bspw. das automatische Erzeugen und Ändern von Konfigurationsdateien oder das automatische Ausführen von Programmen auf dem zu konfigurierenden Server. Die Beschreibung der manuellen Aufgaben/Betriebsprozesse im Betriebshandbuch wird dazu systematisch durch strukturierte Skriptsysteme (bspw. Playbooks) ersetzt.
Infrastructure-as-Code & Orchestrierung
In der nächsten Stufe der Automatisierung wird eine Abstraktionsebene eingezogen, um das was deployt wird von dem wie es konkret deployt wird klar zu trennen. Diese Art der »Provisionierung« wird deklarativ beschrieben. Dazu werden alle Ressourcen und Komponenten, wie Server, Netze, Speicher, Firewalls, Loadbalancer, aber auch externe Dienste und die Instanziierung der IT-Anwendung selbst, mit allen ihren gewünschten Eigenschaften (Konfigurationsparameter) definiert, bspw. als Quellcode in YAML- oder HCL2-Schreibweise. Ein Beispiel für diese Technik ist die OSS Terraform. Hier die Definition eines internen, privaten Netzes:
resource "hcloud_network" "network" {
name = "network"
ip_range = "10.0.0.0/16"
}
Das Prinzip Infrastructure-as-Code (IaC) wird meist so implementiert, dass die spezifische Konfiguration der einzelnen Ziel-Ressourcen mittels gängiger Programmiersprachen erfolgt. Dies kann durch das Erzeugen von Konfigurationsdateien oder zeitgemäß über die Nutzung einer API geschehen. Um die Programmierung zu erleichtern, stellen entsprechende IaC-Plattformen Programmierbibliotheken zur Verfügung (wie bspw. die OSS pulumi), um gängige Programmiersprachen und -umgebungen nutzen zu können. Alternativ werden eigene, spezialisierte Programmiersprachen inklusive Plug-ins/Provider für gängige Ressourcen genutzt (wie bspw. bei der OSS Terraform). Das Deployment wird durch IaC hauptsächlich zur Programmieraufgabe, das heißt der Operator wird zum Entwickler!
Dieser Ansatz kann zusätzlich noch um eine automatische Orchestrierung erweitert werden, bei der die Verteilung des Workloads automatisch zur Laufzeit optimiert wird. Der Orchestrator entscheidet dabei automatisch auf welchem Node ein Programm oder Dienst installiert wird, bspw. in dem er überprüft, auf welchem Node gerade genügend Rechen- und Speicherkapazität verfügbar sind. Generische Orchestratoren, wie bspw. die OSS Nomad, unterstützen als Workload sowohl klassische Programme, die direkt auf dem Betriebssystem eines Nodes ablaufen, als auch Container, bei denen das Programm in einer eigenen Systemumgebung gekapselt wird. Ein derartiger Orchestrator eignet sich daher meistens auch für vorhandene Softwarelösungen (Legacy-Systeme), um diese in ihrer bisher üblichen Systemumgebung zu deployen.
Container-as-a-Service & Operator
Die Revolution im IT-Betrieb des letzten Jahrzehnts dürfte aber Container-as-a-Service darstellen. CaaS wurde mit dem Durchbruch der Container-Technologie (Docker sowie die offene Spezifikation für OCI-Container) in Kombination mit deren Orchestrierung insbesondere mittels Kubernetes ermöglicht. Auch hier wird das Deployment aller Ressourcen deklarativ mittels YAML beschrieben. Allerdings liegt der Fokus auf der Beschreibung der IT-Anwendung selbst, da die grundlegenden IT-Ressourcen wie Nodes, Speicher, Netze u.v.m. bereits in Kubernetes standardmäßig integriert sind. Im Kern beschreibt man die IT-Anwendung durch die Eigenschaften ihrer Dienste (Container und deren Gruppierung als Pods), Sichtbarkeit für andere Services sowie der Veröffentlichung der externen Schnittstellen nach außen ins öffentliche Netz (Ingress).
Durch die offene Art der Kubernetes-API ist die Funktionalität von Kubernetes fast beliebig erweiterbar (Custom Resource Definitions), so dass die Mächtigkeit von Kubernetes ständig steigt, bspw. durch Erweiterungen wie Service Meshes oder Functions-as-a-Service (FaaS). Aber auch die betrieblichen Funktionen der Cloud werden durch die Einführung des Operator Pattern in Kubernetes weiter automatisiert, so dass der IT-Betrieb zunehmend effektiver und damit kostengünstiger wird. Die Operatoren komplementieren dabei die fachlichen Funktionen einer IT-Anwendung um die Betriebsaspekte. Dazu übernehmen sie mittelfristig nicht nur Teile der automatischen Installation einer IT-Anwendung, sondern decken deren kompletten Lebenszyklus ab, bspw. inklusive Datensicherung und -recovery oder Fehlerbehebungen bei bekannten Problemen. Dies ist quasi die Digitalisierung der regulären Administrator-/Operator-Tätigkeiten.
Platform-as-a-Service
Einen ergänzenden Einfluss auf das Modell des klassischen IT-Betriebs hat die DevOps-Bewegung. Bei digital-nativen Unternehmen werden die fachlichen Teams mit der Softwareentwicklung und dem IT-Betrieb eng verknüpft bzw. zusammengeführt. Die technische Umsetzung einer fachlichen Domäne und deren Betrieb erfolgt quasi durch ein interdisziplinäres Team. Die technischen Prozesse werden entsprechend ebenfalls durchgängig automatisiert, dem Continuous Integration/Continuous Deployment (CI/CD). Um solchen Teams mehr Komfort zu bieten, wurden daraus spezielle, integrierte Plattformen abgeleitet (Platform-as-a-Service, PaaS). Diese basieren zwar auf den obigen Standards wie Kubernetes, aber deren Fokus ist die Durchgängigkeit der Software-Entwicklung bis zum Deployment. Diese Spezialisierung vereinfacht teilweise den Entwicklungsaufwand und soll vor allem sicherstellen, dass die Entwickler:innen während der Entwicklungsphase und für die internen Tests selbst eine Deployment-Umgebung nutzen, die zur späteren Produktivumgebung möglichst identisch ist. Dies führt aber zu problematischen Abhängigkeiten insbesondere in traditionellen Organisationen, wo es eine klare Trennung zwischen Softwareentwicklung und IT-Betrieb gibt. Auch kann eine PaaS zu einem Vendor-Lock-in führen. Entweder kann der IT-Betrieb nicht mehr beliebig ausgewählt werden, es müssen zusätzliche Portierungsaufwände in Kauf genommen werden oder die Software-Entwicklung unterliegt starken Einschränkungen, bspw. bei der Auswahl der Entwicklungsumgebung und -werkzeuge.
Function-as-a-Service
Eine weitere, ergänzende Evolutionsstufe von Container-basierten Clouds ist das Konzept Functions-as-a-Service (FaaS). Softwareentwickler:innen implementieren nur noch Funktionen mit der Kernlogik für die Datenverarbeitung und beschreiben durch Abhängigkeiten, bspw.. Ereignissen (Events), indirekt die Aufrufreihenfolge. Dies reduziert den Umfang des zu schreibenden Programmcodes und das Deployment wird durch den FaaS-Orchestrator völlig transparent umgesetzt, der vor allem auch die qualitativen Anforderungen wie Verfügbarkeit und Skalierung automatisch sicherstellt. Die Planung von Infrastruktur und Deployment entfällt quasi bzw. wird stark vereinfacht.
Fazit
Mit der Cloud hat sich auch das Geschäftsmodell bei IaaS und CaaS für IT-Betreiber stark verändert. Statt kundenspezifischer Beschaffungen werden IT-Ressourcen nun produktorientiert pauschal vertrieben, das heißt Kund:innen können vorkonfektionierte IT-Ressourcen aus einem Pool jederzeit anfordern und direkt nutzen. Dies geschieht nicht mehr in Form einzelner, manuell angestoßener Beschaffungsvorgänge, sondern mittels eines Selbstbedienungsportals oder automatisiert über APIs. Verglichen mit der heutigen Bürowelt wird eine IT-Ressource zu einem Bleistift, der ja bei Bedarf auch nicht speziell für eine Mitarbeiterin oder einen Mitarbeiter ausgeschrieben und beschafft wird, sondern in der Materialausgabe meist direkt verfügbar ist.
Alle genannten Varianten für das Deployment sind aus technischer Sicht umsetzbar. Entscheidend ist, dass das bisher gängige Verfahren – die Entwickler:innen werfen eine CD-ROM inkl. Betriebshandbuch »über den Zaun« und der IT-Betrieb sieht zu, wie er es händisch zum Laufen bekommt – durch weitgehend automatisierte Betriebsprozesse abgelöst wird. Wenn man darüber hinaus (sinnvollerweise) auch Komplikationen durch Vendor-Lock-in vermeiden will, sind CaaS und FaaS in Selbstbedienung der Stand der Technik: machbar, verfügbar und vor allem empfehlenswert. Man sollte ferner auch beachten, dass die Komplexität beim Deployment und deren notwendige Automatisierung eigentlich nicht durch die genutzten Plattformen für das Deployment entsteht, sondern eine Folge der Anforderungen der Nutzer:innen an die IT-Anwendung ist – insbesondere der qualitativen Anforderungen.
Schwierig wird es für Fachverantwortliche, wenn dieses Deployment-Level durch den präferierten IT-Betrieb derzeit noch nicht angeboten wird. Dann kann es nach Abwägung der Total Cost of Ownership (TCO) und einer Risikobetrachtung sehr wohl sinnvoll sein, zumindest temporär (bis ein adäquates Deployment-Level durch den IT-Betrieb selbst angeboten wird) auf eine technische Alternative, wie Infrastructure-as-Code aber auch Container-as-a-Service, in Eigenbetrieb zu setzen. Welcher konkrete Ansatz dabei zweckmäßig ist, kann auch von Vorlieben und Vorerfahrungen im eigenen Team abhängen. Langfristig sollte man rechtzeitig auf eine aktuelle Deployment-Umgebung wie Kubernetes wechseln, damit Risiken und Aufwand weiter sinken. Dieser Schritt ist unabdingbar, da die Unterstützung für CaaS als Standardumgebung weiterhin wachsen wird bzw. eine Voraussetzung für neue Funktionalitäten (bspw. Operatoren) ist.
Im Rahmen der ÖFIT-Werkstatt haben wir ein ausführlich dokumentiertes Beispiel für ein Deployment mittels Terraform und Nomad erstellt, um einen konkreten Eindruck zu vermitteln.
Das dazugehörige ÖFIT-Whitepaper kann unter folgendem Link eingesehen werden:
»Cloud-Betrieb im öffentlichen Sektor – Selbstbedienung, Automatisiert«
Jan Gottschick, Uwe Holzmann-Kaiser, Holger Kurrek (2021)
Berlin: Fraunhofer FOKUS: Kompetenzzentrum Öffentliche IT
Weiterführendes von ÖFIT:
Die Cloud wird reichhaltiger, flexibler und dynamischer. In diesem ÖFIT-Paper aus dem Jahr 2014 wird das Thema »Cloud« grundsätzlich angegangen und geschaut, wie die Verwaltung sich dem annähern kann.
»Cloud-Fahrplan für die öffentliche Verwaltung«
Peter H. Deussen, Klaus-Peter Eckert, Petra Hoepner, Christian Hoffmann, Linda Strick (2014)
Berlin: Fraunhofer FOKUS: Kompetenzzentrum Öffentliche IT
Veröffentlicht: 07.10.2021